








A quick and practical guide about how to debug Scrapy projects using PyCharm.
My setup is:
- Scrapy 1.6.0
- Python 3.6
- PyCharm Community Edition 2019.2
- virtualenv
- Linux Mint 19
This turial should work find for older scrapy/python version and for Windows/MacOS.
Note: You can find introduction tutorial for scrapy on this page: Python scrapy tutorial for beginners
Run Scrapy spider from PyCharm terminal
The optimal way for running scrapy spiders is by using terminal because:
- a lot useful information is shown
- you have control on the process
- needs of customization - batching, scheduling, output files - csv, json
In order to run a spider using the PyCharm terminal you can do:
- Open the PyCharm project
- Open terminal dialog - ALT + F12
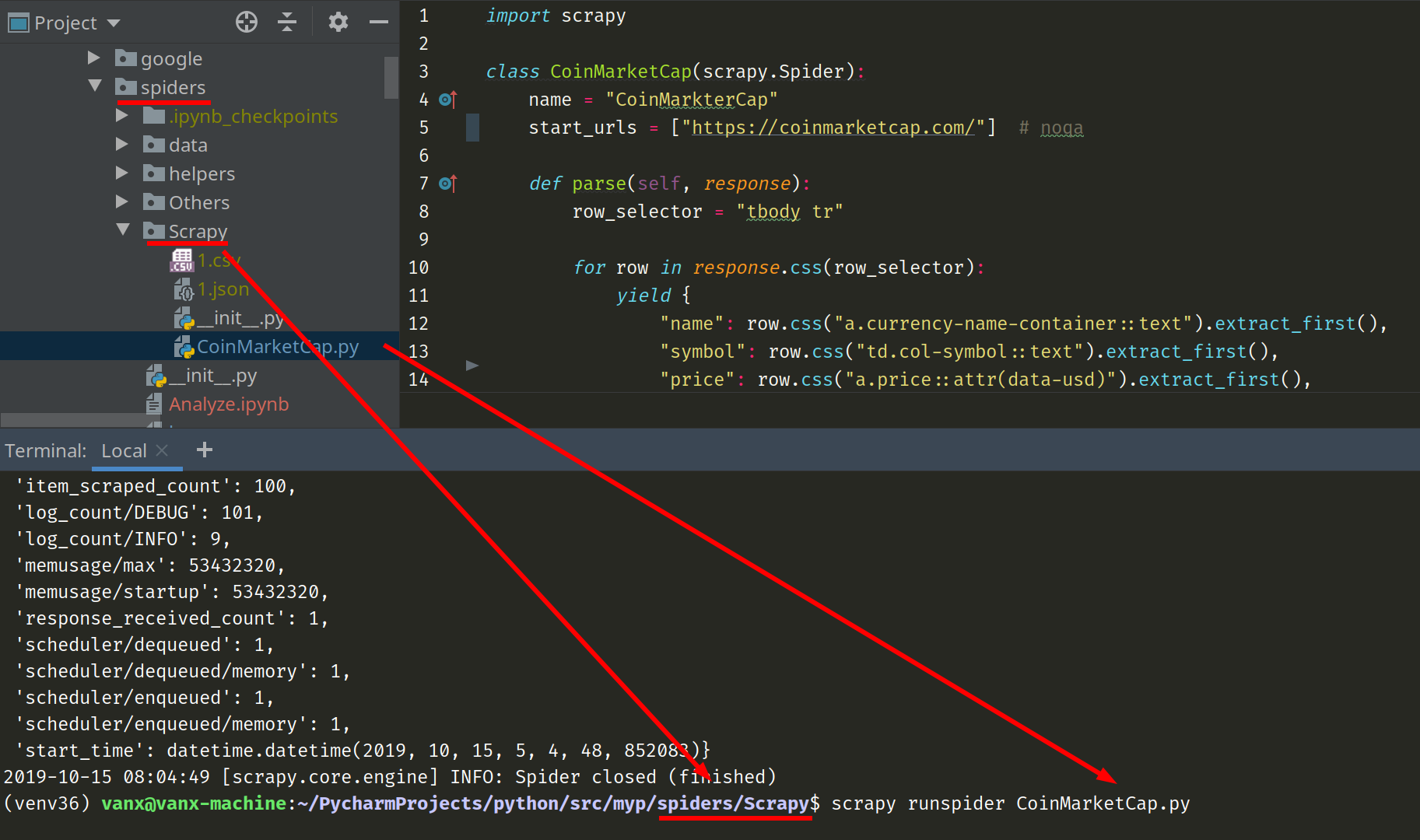
- Navigate in terminal to spider file (you can check the image below)
- Start spider with command
- just for running and getting output in terminal window -
scrapy runspider CoinMarketCap.py - to collect the results as csv file -
scrapy runspider CoinMarketCap.py -o coins.csv
- just for running and getting output in terminal window -
For simple spiders like the one above this will be enough. For more complex spiders and websites you will need to find why some data is not scraped or your spider stop scraping when you expect more data. This is when debugging come to rescue.
Setup configuration for Scrapy debug
Again you will need to open your PyCharm project and spider be prepared. Once you have them you can continue with next steps:
- locate the file in Project browser
- Open the file
- Add breakpoint to the line of your interest
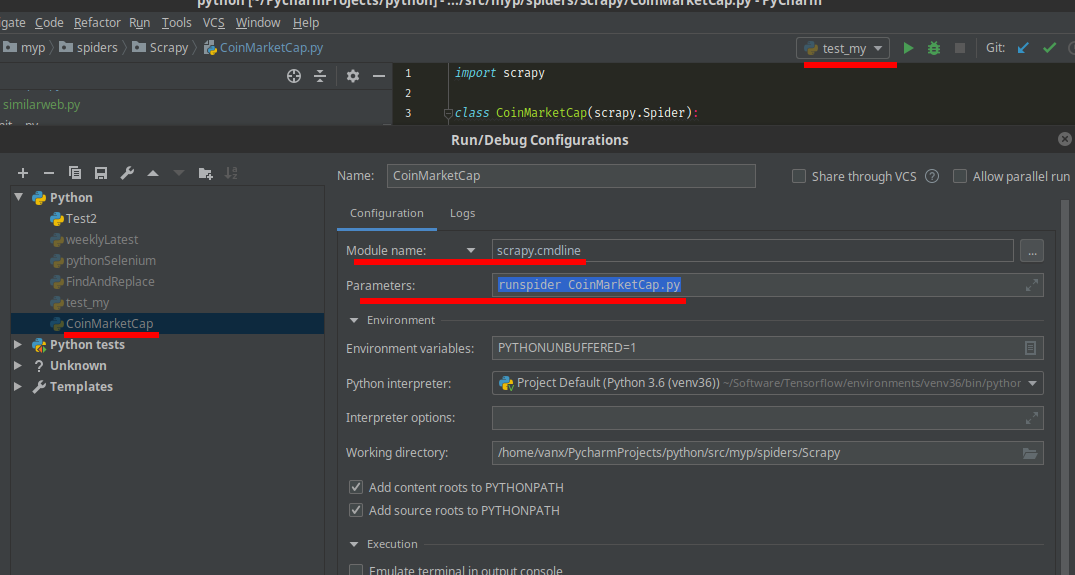
- Run the python file - Shift + F10 - in order to add configuration or you can add it later
- Open Run/Debug Configurations
- top right corner - next to run button
- Main Menu / Run / Edit Configurations
- Change Script path to Module name
- enter
scrapy.cmdline
- enter
- In Parameters
runspider CoinMarketCap.py
- Apply and OK
This configuration is working since PyCharm 2018 for older versions you will need to do:
- Open Run/Debug Configurations
- Enter Scrith path
- locate you scrapy file in the virtual environment or by using
which scrapy - enter the full path -
/home/vanx/Software/Tensorflow/environments/venv36/bin/scrapy
- locate you scrapy file in the virtual environment or by using
- In Parameters
runspider CoinMarketCap.py
Now you can debug the spider.
Additional notes and tips for Scrapy/PyCharm debugging
Scrapy/PyCharm debugging tips
- In order to debug efficiently you can use Evaluate expression feature of PyCharm - Alt + F8 or right click on selected code
- Use Conditional breakpoints - in order to avoid long debugging sessions with Step Over and Step In
- If you more info for PyCharm/IntelliJ debugging - IntelliJ Debug, conditional breakpoints and step back
Note:
There are several commands which can be used:
- scrapy
- runspider
- crawl
all of them are python scripts which means they can be started from terminal or by Pycharm setup above.
In order to see all available commands for module scrapy you can type in PyCharm terminal:
$ scrapy
Result:
Scrapy 1.6.0 - no active project
Usage:
scrapy <command> [options] [args]
Available commands:
bench Run quick benchmark test
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
[ more ] More commands available when run from project directory
Use "scrapy <command> -h" to see more info about a command
And this is the output if you run it from explicit scrapy project:
Scrapy 1.6.0 - project: quotesbot
Usage:
scrapy <command> [options] [args]
Available commands:
bench Run quick benchmark test
check Check spider contracts
crawl Run a spider
edit Edit spider
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
list List available spiders
parse Parse URL (using its spider) and print the results
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
Use "scrapy <command> -h" to see more info about a command
Resources
- If you want to check good educational scrapy project you can check it on this link: quotesbot - This is a sample Scrapy project for educational purposes
- A collection of awesome web crawler,spider in different languages